")
La API de reconocimiento de voz o speech recognition en JavaScript es una API que tenemos disponibles todos los desarrolladores desde HTML5 como la de La API Batería , es una API que nos invita a "hablar" con el navegador, una API con la cual podemos ejecutar comandos de voz con JavaScript o pasar nuestra voz a texto, como vez las formas en las que podemos emplear esta API son infinitas en donde nuestra imaginación es el límite y hasta librerías podemos crear o emplear.
Con esta API HTML5 podemos ejecutar comandos de voz acorde a nuestra data, ya que la lógica la implementamos nosotros
Por nombrar algunas de las muchas APIs de JavaScript que se han visto.
Trabajar con reconocimiento de voz en JavaScript es una de esas cosas que parecen complejas… hasta que usas la Web Speech API y descubres que en realidad puedes convertir voz en texto, crear comandos por voz o validar pronunciación con apenas unas líneas de código.
En mi caso, he usado esta API para una app de idiomas en la que, cuando el usuario pronuncia una palabra, mi aplicación reproduce el audio correcto si el reconocimiento coincide. Y déjame decirte: no solo funciona, sino que abre un mundo entero de posibilidades.
En esta guía te explico todo lo que necesitas saber, desde lo básico hasta integración avanzada, errores comunes y ejemplos en español.
Qué es la Web Speech API y cómo funciona el reconocimiento de voz
La Web Speech API ofrece dos funciones principales:
- SpeechRecognition → convertir voz en texto: Captura voz y la convierte en texto. Ideal para comandos, dictado, apps de idiomas.
- SpeechSynthesis → convertir texto en voz: Habla texto en voz alta. Muy útil si quieres respuestas habladas en tu app.
El motor de reconocimiento suele depender del navegador. En Chrome, por ejemplo, tu audio se envía a un servidor, por lo que la API no funciona offline y puede ser usado para dictado por voz con JavaScript.
"La API en JavaScript que nos invita a hablar con las aplicaciones"
En esta entrada daremos los primeros pasos con la API de Reconocimiento de Voz
speechRecognition()en JavaScript que en otras palabras da la capacidad a nuestras aplicaciones de reconocer la voz según el idioma configurado a través del micrófono de la PC o dispositivo móvil.
Limitaciones actuales (Chrome, permisos, HTTPS)
- Chrome solo permite acceso al micrófono si la web tiene HTTPS o estás en localhost.
- Solo funciona totalmente bien en Chrome y Android.
- iOS tiene soporte parcial.
Comenzando con la API de Reconocimiento de Voz en JavaScript
El esqueleto del código que emplearemos es el siguiente y lo analizaremos en la siguiente sección:
if (!('webkitSpeechRecognition' in window)) {
alert("¡API no soportada!");
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.lang = "es-Ve";
recognition.onstart = function() {}
recognition.onresult = function(event) {}
recognition.onerror = function(event) {}
recognition.onend = function() {}
}O la forma más completa:
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();Al igual que pasa con todas las APIs "nuevas", es necesario verificar la disponibilidad de la API de Reconocimiento de Voz en el navegador consultando si el objeto webkitSpeechRecognition existe; si no existe, simplemente se muestra un mensaje diciendo que la API no se encuentra disponible en su navegador:
if (!('webkitSpeechRecognition' in window)) {
alert("¡API no soportada!");
}else{
...
}Si la API de Reconocimiento de Voz se encuentra disponible o está implementada en el navegador, se ejecuta la siguiente sección de código encerrada por el else; la primera línea de código:
recognition.continuous = true;Inicializa el atributo continuous (establecido en false por defecto) con el objetivo de definir la continuidad al momento de hablar; es decir, se establece que cuando el usuario deje de hablar, el Reconocimiento de Voz llega a su fin (se dispara el evento onend).
Esta otra línea de código:
recognition.interimResults = true;Especifica si los resultados devueltos son definitivos y no cambiarán (false) o no (true).
La siguiente línea de código:
recognition.lang = "es-VE";Inicializa el atributo lang que especifica el lenguaje que va ha ser reconocido a realizar la petición; en otras palabras, el lenguaje a emplear por el usuario.
Eventos principales de la API de Reconocimiento de Voz en JavaScript
Una vez establecidos los atributos anteriores, ahora es el turno de los eventos que son los que realmente permitirán controlar y obtener las palabras del usuario en texto plano:
- onstart: cuando empieza a escuchar
- onresult: cuando llega un resultado
- onend: cuando termina la escucha
- onerror: error genérico (falta de permisos, ruido, etc.)
recognition.onstart = function() {}
recognition.onresult = function(event) {}
recognition.onerror = function(event) {}
recognition.onend = function() {}El evento onstart de la API SpeechRecognition
Este evento se ejecuta cuando la función start() es invocada el navegador empieza a "escuchar"; en otras palabras, representa el momento en el cual la aplicación comienza a escuchar; para invocar al evento onstart debemos hacer lo siguiente:
var recognition = new webkitSpeechRecognition();
...
recognition.start();El evento onerror de la API SpeechRecognition
Este evento se ejecuta si y sólo si ha ocurrido algún error, aquí podemos expresar a nuestro usuario el error para que el lo solucione, si no se encontró micrófono o los permisos del mismo.
El evento onend de la API SpeechRecognition
Este evento se ejecuta cuando el usuario ha acabado de hablar, lo que significa que el reconocimiento de voz a llegado a su fin; es un buen candidato para hacer algún cambio a nivel visual en nuestra API, para que el usuario sepa que ya no se le está escuchando y que se va a realizar el procesamiento de lo que él expresó mediante voz.
El evento onresult de la API SpeechRecognition
Finalmente, este evento devuelve el resultado obtenido; dicho de otra forma, las palabras expresadas de forma verbal convertido en texto plano; como puedes darte cuenta, este es el método "fuerte" de esta API y es donde podemos procesar la ansiada respuesta de nuestro usuario en formato texto; nosotros no tenemos que hacer nada con audio, la API hace todo por nosotros y nos da el equivalente en texto de lo que expresa el usuario mediante voz.
Esta es la parte interesante de la API; aquí conseguimos finalmente la respuesta obtenida por el usuario en la siguiente estructura:
{
..
results: {
0: {
0: {
confidence: 0.6...,
transcript: "Hola"
},
isFinal:true,
length:1
},
length:1
},
..
}Para obtener el último párrafo pronunciado por el usuario podemos hacer lo siguiente:
if(event.results[i].isFinal)
event.results[i][0].transcript;Ejemplo completo de la API de Reconocimiento de Voz en JavaScript: Voz a Texto
Ya explicado la parte "fuerte" del código o lo que es lo mismo lo básico de la API es posible crear un pequeño programa que permite emplear el Reconocimiento de Voz en una aplicación web y mostrar el resultado en un campo de texto:
var recognition;
var recognizing = false;
if (!('webkitSpeechRecognition' in window)) {
alert("¡API no soportada!");
} else {
recognition = new webkitSpeechRecognition();
recognition.lang = "es-VE";
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() {
recognizing = true;
console.log("empezando a escuchar");
}
recognition.onresult = function(event) {
for (var i = event.resultIndex; i < event.results.length; i++) {
if(event.results[i].isFinal)
document.getElementById("texto").value += event.results[i][0].transcript;
}
//texto
}
recognition.onerror = function(event) {
}
recognition.onend = function() {
recognizing = false;
document.getElementById("procesar").innerHTML = "Escuchar";
console.log("terminó de escuchar, llegó a su fin");
}
}
function procesar() {
if (recognizing == false) {
recognition.start();
recognizing = true;
document.getElementById("procesar").innerHTML = "Detener";
} else {
recognition.stop();
recognizing = false;
document.getElementById("procesar").innerHTML = "Escuchar";
}
}Dando algunas consideraciones sobre el código anterior:
- Empleamos la variable
recognizingpara saber fácilmente cuando está o no "escuchando" el navegador. - Actualmente no podemos emplear esta API en sitios que no tengan conexión HTTPS.
Con este sencillo ejemplo vemos lo fácil que resulta convertir texto a voz empleando la API nativa de HTML5 para el reconocimiento de voz.
Problemas con los navegadores en el reconocimiento de voz
Recuerda que por seguridad para emplear los dispositivos como micrófonos y cámaras desde navegador si la web no cuenta con el certificado HTTPS la solicitud de acceder ya sea a la cámara o micrófono del dispositivo no funcionará, esto trae muchos problemas si no tenemos dicho certificado HTTPS en nuestra web o la web en donde queramos emplear el script para acceder a la cámara web o micrófono del dispositivo.
Manejo de los permisos en Google Chrome
Google Chrome tiene un sistema de permisos de los dispositivos que pueden ser accedidos a las distintas web; para ello nos ubicamos en el script desarrollado en esta entrada (o cualquier otro que intente acceder al micrófono de nuestro equipo) y vamos al pequeño icono que se nos presenta en la barra de navegación ubicado en la esquina superior derecha y damos un clic sobre el mismo; el problema que existe con las versiones recientes de Google Chrome es que sin importar la opción que seleccionemos:

Google Chrome nunca nos permite acceder al micrófono a ninguna web que no tenga el certificado HTTPS salvo que sea localhost.
y damos clic sobre "Administrar configuración de micrófono":
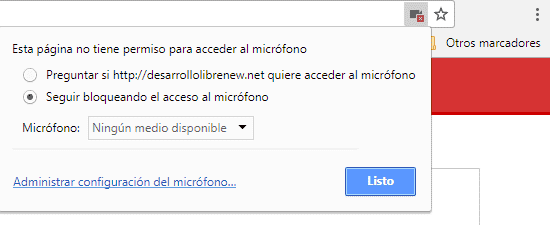
Aquí podemos ver las web las cuales tienen permitidas acceder a nuestro micrófono; como un punto importante vemos que Google Chrome permite acceder al micrófono si estamos accediendo desde el localhost, asi que si copiamos el script provisto en esta entrada y lo copiamos en nuestro localhost el mismo podrá funcionan correctamente en el momento en que Google Chrome solicite el permiso y posteriormente le asignemos el mismo. Un punto importante es que NO veremos ninguna web en esta sección que no tenga el certificado HTTPS no importa que opción coloquemos en la ventana anterior.
Extra comando de voz con una librería JavaScript
En este complemento que les traemos, vamos a ver cómo procesar comando de voz con la librería annyang en JavaScript; recuerda que necesitas un servidor web con HTTPS o desde el localhost; el funcionamiento es sencillo, solo debemos de indicar los comandos de voz:
var commands = {
// annyang will capture anything after a splat (*) and pass it to the function.
// e.g. saying "Show me Batman and Robin" is the same as calling showFlickr('Batman and Robin');
'show me *tag': showFlickr,
// A named variable is a one word variable, that can fit anywhere in your command.
// e.g. saying "calculate October stats" will call calculateStats('October');
'calculate :month stats': calculateStats,
// By defining a part of the following command as optional, annyang will respond to both:
// "say hello to my little friend" as well as "say hello friend"
'say hello (to my little) friend': greeting
};Y luego definimos las funciones que vamos a emplear, una función por cada comando:
var showFlickr = function (tag) {
$('#frace').text("Tag: " + tag);
console.log("Tag: " + tag)
}
var calculateStats = function (month) {
$('#frace').text("Data de " + month);
console.log("Data de " + month)
}
var greeting = function () {
$('#frace').text("Hola Mundo");
console.log("Hola Mundo")
}Por último agregamos los comando, de manera opcional el idioma a emplear y start() para iniciar todo.
// Agregamos nuestros comandos a annyang.
annyang.addCommands(commands);
//Establecemos el lenguaje
annyang.setLanguage("es-MX");
// Empezamos a escuchar.
annyang.start();Aunque si no quiere emplear una librería externa y solo quieres emplear la API nativa provista en HTML5, también puedes hacerlo, puedes hacerlo de muchas formas, si vas a crear comandos simples puedes comparar el texto devuelto por el usuario completamente, si te interesa agarrar palabras claves, puedes emplear la función indexOf provista por la API de JavaScript; sin son varios comandos, pues usas un switch o un if agrupado; todas estas consideraciones las debes tomar en la función onresul:
recognition.onresult = function(event) {
for (var i = event.resultIndex; i < event.results.length; i++) {
if(event.results[i].isFinal)
document.getElementById("texto").value += event.results[i][0].transcript;Ejemplo simplificado
Aquí tienes un ejemplo más sencillo de lo realizado anteriormente:
<button onclick="recognition.start()">Hablar</button>
<p id="texto"></p>
<script>
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
recognition.lang = "es-ES";
recognition.continuous = true;
recognition.onresult = (event) => {
const texto = event.results[event.results.length - 1][0].transcript;
document.getElementById("texto").innerText = texto;
};
</script>Cómo implementar comandos de voz sin librerías
Puedes empezar con algo tan simple como:
if (texto.includes("abrir wikipedia")) {
window.open("https://es.wikipedia.org/wiki/Wikipedia:Portada");
}Manejo con switch o includes:
switch (true) {
case texto.includes("play"):
reproducirAudio();
break;
case texto.includes("siguiente"):
pasarAlSiguiente();
break;
}Ejemplo práctico (comandos en español)
if (texto.toLowerCase().trim() === "reproducir audio") {
audioElement.play();
}Reconocimiento de voz en una app de idiomas
Podemos hacer aplicaciones tipo Duolingo, en la cual, podemos comprobar la pronunciación del usuario:
recognition.onresult = (event) => {
const dicho = event.results[event.results.length - 1][0].transcript.toLowerCase().trim();
if (dicho === objetivo) validarPronunciacion();
};Si es OK, reproducimos un audio:
function validarPronunciacion() {
document.getElementById("audio-perro").play();
}Problemas comunes que encontré
- Palabras muy parecidas (“pero / perro”) pueden confundirse.
- Si hay ruido de fondo, debes usar frases más largas.
- Cambiar entre varios idiomas (español, inglés) requiere reconfigurar recognition.lang entre escuchas.
Errores habituales y cómo resolverlos
- Chrome bloquea el micrófono (HTTPS obligatorio)
- Si estás en HTTP, verás errores como:
- DOMException: Permission deniedSolución:
- usar localhost o activar HTTPS (Let’s Encrypt funciona perfecto)
- No se detecta ningún audio
- Puede deberse a:
- micrófono mal configurado
- ruido ambiental
- permisos bloqueados
- Puede deberse a:
- Permisos denegados (getUserMedia)
navigator.mediaDevices.getUserMedia({ audio: true }) .catch(() => console.log("Sin permiso de micrófono"));- Eventos “no-speech” y “network”
- Estos ocurren cuando:
- no se escuchó ninguna palabra
- hubo caída de conexión
- Chrome no pudo enviar el audio al servidor
Ideas interesantes para implementar en proyecto
- Gramáticas JSGF para vocabularios cerrados
- Perfectas para apps donde solo se aceptan palabras concretas:
- var grammar = ‘#JSGF V1.0; grammar colors; public <color> = rojo | azul | verde ;’
- Usar SpeechSynthesis como feedback por voz
new SpeechSynthesisUtterance("Correcto, lo pronunciaste bien");
- Librerías como annyang
- Útil si quieres comandos avanzados:
annyang.addCommands({ "hola mundo": () => console.log("¡Hola!") }); annyang.start();
Preguntas frecuentes
- ¿Funciona offline?
- No. Chrome envía tu voz a un servidor.
- ¿Cómo uso varios idiomas?
- Cambia recognition.lang antes de cada start().
- ¿Es viable para apps de idiomas?
- Sí, de hecho yo mismo la uso para validar pronunciación y reproducir audio según lo dicho.
- ¿Puedo usarlo en móvil?
- En Android sí. En iOS es limitado.
Conclusión
El reconocimiento de voz en JavaScript es una herramienta poderosa, sencilla y perfecta para proyectos interactivos: apps de idiomas, asistentes de voz, formularios hablados o sistemas de comandos.
Lo mejor es que no necesitas librerías externas: basta con SpeechRecognition, algunos eventos y un poco de lógica. Con la estructura adecuada y controlando permisos y errores, puedes construir funcionalidades de voz totalmente profesionales.
Ahora, aprende a escribir, leer y drag and drop de archivos con JavaScript.