
Índice de contenido
- Por qué una mala estructura te pasa factura
- Qué significa Clean Code aplicado a FastAPI
- Clean Code no es escribir más capas
- Principios que realmente importan en una API
- Clean Architecture como consecuencia natural
- Separación de responsabilidades en FastAPI
- Capas y dependencias: hacia dónde debe apuntar el código
- Herramientas: Gemini Antigravity
- Preparación y Conceptos de Arquitectura
- ¿Qué es la Clean Architectures y Clean Code?
- Clean Code vs Clean Architecture
- El Prompt y la Refactorización
- Ejecución del Plan
- El Problema de los WebSockets
- Resultado
- Interface Adapters
- Use Cases (Casos de Uso)
- Entities (Entidades)
- Frameworks & Drivers
- En esta carpeta, puedes ver la implementación más fuerte de las tecnologías que NO son de nosotros y que podemos cambiar en cualquier momento, como viene siendo, FastAPI y la base de datos con SQLAlchemy.
- Dependencias y patrón Repository en FastAPI
- ¿Qué es el Patrón Repository?
- ¿Por qué es útil?
- Más allá de cambiar la base de datos
- Estructura básica del patrón Repository
- 2. La implementación (adaptador)
- 3. La capa de acceso mediante dependencias
- 4. Consumo desde el endpoint
- Ejemplo práctico de cambio de base de datos
- Caso real: mi propia aplicación
- Relación con arquitectura hexagonal que implementamos antes
- Ventajas Reales (Caso de Uso)
- Beneficios reales de aplicar Clean Code en FastAPI
- Código más fácil de mantener y testear
- Escalar sin miedo a romperlo todo
- Errores comunes al aplicar Clean Architecture en FastAPI
- Copiar arquitecturas sin entenderlas
- Convertir Clean Code en burocracia
- Conclusión: Clean Code para no volver a empezar de cero
- Preguntas frecuentes sobre Clean Code en FastAPI
Vamos a realizar un pequeño experimento. Tomaremos nuestro proyecto actual, el cual no sigue precisamente las mejores prácticas organizativas -ya que nació como una prueba rápida para implementar WebSockets-, y vamos a mejorar su estructura, y esto lo hacemos siguiendo las buenas prácticas como presentamos antes con El ciclo de vida de una app en FastAPI con los eventos Lifespan
Para ello, utilizaremos arquitecturas de software establecidas. No pretendo que esto sea un curso profundo de Go o de arquitecturas avanzadas, sino más bien una presentación para despertar tu curiosidad. Más adelante podremos dedicarle una sección completa o un curso específico, o si lo prefieres, puedes investigar por tu cuenta. Es el momento ideal para este experimento, ya que la aplicación es pequeña y manejable.
Los proyectos empiezan pequeños, como casi todos. Un par de endpoints, algo de lógica en las rutas, una conexión a base de datos… todo parecía razonable. Pero a medida que el código crecía, mantener una buena estructura dejó de ser opcional. Fue ahí cuando descubrí Clean Code aplicado a FastAPI y entendí algo clave: ¿para qué reinventar la rueda si el problema ya está resuelto?
En este artículo te explico cómo aplicar Clean Code en FastAPI de forma práctica, sin dogmas ni sobre-ingeniería, para que tu API pueda crecer sin convertirse en un caos.
Por qué una mala estructura te pasa factura
FastAPI no te obliga a estructurar nada. Y eso es una ventaja… hasta que deja de serlo.
Los síntomas típicos:
routersgiganteslógica duplicada
tests imposibles de escribir
miedo a tocar código “porque seguro rompe algo”
En mi caso, el crecimiento del proyecto fue el detonante. No estaba escribiendo mal código, pero sí estaba escribiendo código que no estaba preparado para crecer.
Qué significa Clean Code aplicado a FastAPI
Clean Code no es escribir más capas
Un error común es pensar que Clean Code significa:
“Más carpetas, más clases y más abstracciones”.
No.
Clean Code en FastAPI significa:
responsabilidades claras
dependencias bien dirigidas
código fácil de leer, testear y modificar
No se trata de seguir una arquitectura por moda, sino de resolver problemas reales de mantenimiento.
Principios que realmente importan en una API
Al aplicar Clean Code en FastAPI, estos principios son los que marcan la diferencia:
Separación de responsabilidades
HTTP no es lógica de negocio.Dependencias hacia adentro
La lógica no depende de frameworks.Código explícito
Que se entienda qué hace sin leer cinco archivos.Facilidad para testear
Sin levantar FastAPI ni una base de datos real.
Cuando entendí esto, Clean Architecture dejó de parecer algo “académico” y pasó a ser una consecuencia natural.
Clean Architecture como consecuencia natural
Separación de responsabilidades en FastAPI
Una API bien estructurada suele dividirse en capas conceptuales:
API / Presentation → FastAPI, rutas, request/response
Application → casos de uso
Domain → reglas de negocio
Infrastructure → base de datos, servicios externos
La clave: FastAPI vive en la capa más externa.
Capas y dependencias: hacia dónde debe apuntar el código
La regla de oro:
Las capas internas no saben que FastAPI existe.
Eso te permite:
cambiar FastAPI por otro framework,
cambiar la base de datos,
testear la lógica sin HTTP.
Y aquí es donde muchos proyectos se rompen si no hay una estructura clara desde temprano.
Herramientas: Gemini Antigravity
Para este trabajo utilizaré Gemini Anti-Gravity, el editor que ves en pantalla. Si no lo conoces, es similar a herramientas como Windsurf o muchas otras que están surgiendo. Es una bifurcación de VS Code que permite interactuar con la IA de manera más efectiva mediante agentes integrados en el espacio de trabajo.
Una de sus opciones más interesantes es la de Planning (Planificación). A diferencia de otras extensiones para VS Code, esta herramienta genera una "hoja de ruta" antes de aplicar cualquier cambio. Esto es extremadamente útil porque te permite revisar y ajustar el plan antes de que la IA modifique tu código.
Preparación y Conceptos de Arquitectura
Antes de pedir cambios globales a la IA, es fundamental sincronizar tu proyecto con GitHub. Las cosas pueden salir mal, y tener un respaldo te ahorrará mucho tiempo si necesitas revertir cambios.
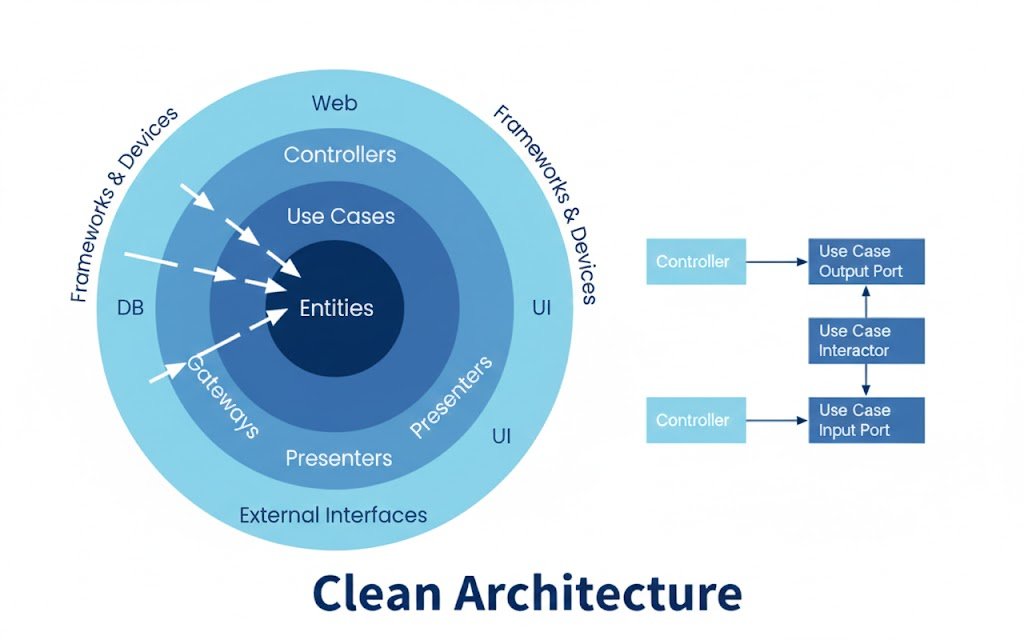
¿Qué es la Clean Architectures y Clean Code?
Seguramente has oído hablar de la Clean Architectures, Arquitectura limpia y el Clean Code, vamos a ver que es cada uno de ellos.
Clean Code vs Clean Architecture
Es importante aclarar algo:
- Clean Code no es una arquitectura, es una filosofía.
- Se enfoca en escribir código simple, modular, legible y mantenible.
- Clean Architecture es la aplicación práctica de esos principios.
Es como la diferencia entre API y REST API: uno es el concepto general y el otro es su aplicación concreta.
En esencia el Clean Code, son formas de organizar el código basadas en buenos principios. Nosotros ya hemos aplicado algo de esto al separar esquemas y modelos, pero de forma incompleta. La idea de usar una arquitectura existente es no reinventar la rueda. En lugar de inventar nombres para nuestras carpetas, usamos estructuras probadas que hacen que el código sea legible, mantenible y escalable.
La estructura que buscamos generar se divide generalmente en:
- Entities (Entidades): La lógica de negocio más pura.
- Use Cases (Casos de Uso): Acciones específicas (ej. crear un usuario, login). Es el corazón de la lógica de negocio. Aquí se define qué pasa cuando un usuario hace login, independientemente de si la petición viene de una API REST o de un WebSocket.
- Aquí está la lógica real del sistema.
- Por ejemplo, en el login:
- Verificamos usuario.
- Validamos contraseña.
- Generamos token.
- Antes, esto estaba dentro del endpoint.
- Ahora está desacoplado.
- Eso permite que:
- No dependa del tipo de respuesta.
- No dependa de FastAPI.
- Pueda reutilizarse.
- Interface Adapters: Controladores y repositorios que traducen datos. Actúan como traductores. Aquí están los controladores que reciben peticiones HTTP y los repositorios que manejan los datos.
- Son los traductores.
- Reciben:
- Peticiones HTTP
- WebSocket
- XML
- JSON
- Y traducen esas entradas hacia los casos de uso.
- Frameworks & Drivers: Herramientas externas como la base de datos o el framework web (FastAPI). Aquí reside el código que "no es nuestro", como la configuración de FastAPI o la conexión a la base de datos (SQLAlchemy). Si mañana queremos cambiar FastAPI por Flask, solo deberíamos tocar esta capa.
- Aquí va el código que no es nuestro:
- FastAPI
- Conexión a base de datos
- ORM
- Mongo, SQLite, Firebase, etc.
- Si mañana cambiamos FastAPI por Flask, los cambios estarían aquí.
- Aquí va el código que no es nuestro:
El Prompt y la Refactorización
Para que la IA sea efectiva, necesitamos un buen Prompt. He utilizado una IA para generar la instrucción que le daremos a nuestro agente de código. El resultado fue el siguiente:
"Actúa como un experto en arquitectura de software. Refactoriza mi aplicación FastAPI siguiendo los principios de Clean Code. Separa el código en capas de Entities, Use Cases, Interfaces y Adapters. Implementa el patrón Repositorio para el acceso a datos, asegurando que las dependencias apunten hacia adentro. Genera la nueva estructura de carpetas y los archivos correspondientes."
Ejecución del Plan
Al activar la opción de Planning, la IA nos muestra qué archivos creará y qué carpetas moverá. En este caso, creará una carpeta src con subcarpetas para entidades, casos de uso (como login_use_case.py) y repositorios.
El Problema de los WebSockets
Durante la refactorización, hubo un pequeño error con los WebSockets debido a la confusión entre versiones del proyecto. La IA inicialmente generó un socket muy simple que solo devolvía texto. Tuve que pedirle una corrección específica:
"Adapta el endpoint de WebSockets llamado websocket_endpoint a la arquitectura limpia, integrando el manejador de conexiones (ConnectionManager) que teníamos anteriormente."
Resultado
Veamos algunos códigos importantes para entender la estructura anterior:
Archivo en su mínima expresión que es el punto de entrada de la aplicación, en el cual, accemos a los controladores:
main.py
"""Application entry point."""
from src.frameworks_drivers.http.app import appsrc/frameworks_drivers/http/app.py
from src.interface_adapters.controllers import (
auth_controller,
alerts_controller,
rooms_controller,
websocket_controller
)
***
# Include routers with /api prefix
app.include_router(auth_controller.router, prefix="/api")
app.include_router(alerts_controller.router, prefix="/api")
app.include_router(rooms_controller.router, prefix="/api")Interface Adapters
Aquí se encuentran los controladores, que es la puerta de entrada de nuestra app, aunque, si es cierto que resulta imposible cumplir al 100% con los principios del Clean Code, en esta capa NO debería haber nada de código de FastAPI, aquí tenemos los controladores de FastAPI, que en resumen, siguiendo el esquema MVC, es la capa imptermedia, la de control que conecta la Vista con los Modelos:
src/interface_adapters/controllers/alerts_controller.py
@router.get("/alerts", response_model=List[Alert])
def get_alerts(
room_id: Optional[int] = None,
user: User = Depends(get_current_user),
alert_repo=Depends(get_alert_repository)
):
"""Get alerts endpoint with optional room filtering."""
use_case = GetAlertsUseCase(alert_repo)
alerts = use_case.execute(room_id=room_id)
# Convert entities to ORM-compatible format for Pydantic
return [
{
"id": alert.id,
"content": alert.content,
"created_at": alert.created_at,
"user_id": alert.user_id
}
for alert in alerts
]En el ejemplo de controlador anterior, vemos que la base de datos se inyecta como una dependencia, ya que, puede ser cualquier cosa, una base de datos en MariDB, PSQL, un JSON, Firebase, un archivo y por los principios del Clean Code, se maneja de esta forma para que sea débilmente acoplada, lo que significa, que podemos cambiar la fuente de datos sin romper con los controladores u otras capas.
Ademas, usamos los casos de usos en donde se maneja la lógica de negocios.
Use Cases (Casos de Uso)
src/use_cases/auth/login.py
"""Login Use Case - Handles user authentication."""
from typing import Optional
import bcrypt
from src.entities.user import User
from src.entities.token import Token
from src.interface_adapters.repositories.repository_interfaces import (
UserRepositoryInterface,
TokenRepositoryInterface
)
class LoginUseCase:
"""Use case for user login."""
def __init__(
self,
user_repository: UserRepositoryInterface,
token_repository: TokenRepositoryInterface
):
self.user_repository = user_repository
self.token_repository = token_repository
def execute(self, username: str, password: str) -> Optional[str]:
"""
Execute login use case.
Args:
username: User's username
password: User's plain password
Returns:
Token key if successful, None otherwise
"""
# Get user by username
user = self.user_repository.get_by_username(username)
if not user:
return None
# Verify password
if not self._verify_password(password, user.password):
return None
# Get or create token
token = self.token_repository.get_by_user_id(user.id)
if not token:
import secrets
token = Token(
key=secrets.token_hex(20),
user_id=user.id
)
token = self.token_repository.create(token)
return token.key
@staticmethod
def _verify_password(plain_password: str, hashed_password: str) -> bool:
"""Verify password against hash."""
password_byte_enc = plain_password.encode('utf-8')
hashed_password_enc = hashed_password.encode('utf-8')
return bcrypt.checkpw(password_byte_enc, hashed_password_enc)En este módulo tenemos la lógica de nuestra empresa o negocio, no le importa de donde salen los datos ni el formato esperado, esta capa usa una entidad genética (ni los modelos de Pydantic ni el ORM); al ser la lógica de negocios, en nuestro caso, un usuario autenticado, manejamos los casos que cubriamos en la Rest API:
rest_api.py
@router.post("/login")
def login(request: schemas.LoginRequest, db: Session = Depends(get_db)):
user = db.query(models.User).filter(models.User.username == request.username).first()
if not user:
return JSONResponse("User invalid", status_code=status.HTTP_401_UNAUTHORIZED)
if not verify_password(request.password, user.password):
return JSONResponse("Password invalid", status_code=status.HTTP_401_UNAUTHORIZED)
# Get or Create Token
token = db.query(models.Token).filter(models.Token.user_id == user.id).first()
if not token:
token = models.Token(user_id=user.id)
db.add(token)
db.commit()
db.refresh(token)
return {"token": f"Token_{token.key}"}Pero con una mayor abstracción, como comentamos antes, a los casos de uso NO le importa el fuente de datos (Base de datos u otro) o el tipo de retorno (que no es especifico, ya que, pudieramos emplear este caso de uso como respuesta de una API -lo que tenemos- o desde un template con Jinja u otro…) y usa una entidad genérica nuevamente NO acoplada a ningun framework que es la siguiente capa.
Entities (Entidades)
Tenemos 3 tipos de entidades, las dos que teníamos en nuestro proyecto de FastAPI que están fuertemente acopladas a la tecnología, que en este ejemplo es FastAPI:
src/frameworks_drivers/db/orm_models.py
src/interface_adapters/presenters/schemas.py
Que están definidas en el ORM (fuertemente ligado a código que no es de nosotros como lo es la base de datos con SQLAlchemy) y los esquemas de Pydantic (que aunque son usados por FastAPI, por definición, son traductores para el proyecto de FastAPI)
Y finalmente, tenemos clases aisladas, de tipo data class, que al igual que en Kotlin son clases cuyo propósito es presentar los datos:
src/entities
"""Alert entity - Core business model."""
from dataclasses import dataclass
from datetime import datetime
from typing import Optional
@dataclass
class Alert:
"""Alert entity representing a message in a room."""
id: Optional[int]
content: str
user_id: int
room_id: int
created_at: Optional[datetime] = NoneY por lo tanto, siguiendo con los principios del Clean Code, las aplicaciones deben de tener un acoplamiento debil y por ende, podemos cambiar de framework o tecnología (pasar a Django o Flask que NO utilizan modelos de Pydantic) que los casos de usos NO se verán alterados, lo cual si sucedería si empleamos en lugar de estas entidades una clase de Pydantic.
Frameworks & Drivers
En esta carpeta, puedes ver la implementación más fuerte de las tecnologías que NO son de nosotros y que podemos cambiar en cualquier momento, como viene siendo, FastAPI y la base de datos con SQLAlchemy.
Dependencias y patrón Repository en FastAPI
Además, todo lo anterior, también está relacionado con la eficiencia y la velocidad de FastAPI. Si lo comparamos con otros frameworks, suele ser 5, 7 o incluso 10 veces más rápido, dependiendo de la implementación. Esa comparación puedes buscarla en internet sin problema.
El patrón Repository nos ayudará a entender mejor por qué las dependencias son tan importantes en este punto.
Como resumen del ejemplo anterior, inicialmente tenemos:
- Una API para consumir algo llamado habitaciones (rooms).
- Un recurso llamado alertas, que básicamente son mensajes.
- Modelos para almacenar los datos.
- Modelos del usuario autenticado.
- La parte de la REST API.
- Y el WebSocket definido.
Es un ejercicio pequeño, pero muy interesante para luego pedirle a la IA que implemente el patrón Repository dentro de una arquitectura hexagonal con el Patrón Repository y separe los módulos correctamente.
¿Qué es el Patrón Repository?
El Patrón Repository es un mecanismo de abstracción que nos permite independizarnos de cómo y dónde almacenamos los datos.
En un desarrollo tradicional, solemos estar "atados" a una base de datos específica mediante un ORM (como SQLAlchemy). Si bien los frameworks modernos como Django o Flask permiten cambiar de motor (de MySQL a PostgreSQL, por ejemplo) con relativa facilidad, el Patrón Repository va un paso más allá: nos permite cambiar la fuente de datos completa sin tocar la lógica de negocio.
¿Por qué es útil?
Imagina que tu proyecto crece y, por requerimientos del cliente o del jefe, ya no puedes usar una base de datos relacional. Ahora necesitas consumir una API externa (como Firebase o Supabase), un archivo JSON o incluso un Excel. Sin este patrón, tendrías que reescribir casi toda la aplicación. Con él, solo cambias una capa.
Más allá de cambiar la base de datos
Con Repository no solo puedes cambiar el motor de base de datos. También puedes cambiar completamente la fuente de datos:
- Una API externa.
- Firebase.
- Supabase.
- Un archivo JSON.
- Un Excel.
- Cualquier otra fuente.
Y lo puedes hacer sin romper tu aplicación.
Si lo haces de forma tradicional, referenciando directamente modelos en todas partes (siguiendo algo tipo MVC clásico), cuando cambias la fuente de datos, explota todo.
Con Repository, no.
Estructura básica del patrón Repository
1. La interfaz (contrato)
En Python, definimos una interfaz usando clases abstractas (ABC). Su propósito es definir una "firma": qué métodos deben existir (get, create, delete), pero no cómo funcionan.
Esta interfaz define las firmas que deben implementarse:
- Obtener todos.
- Obtener por ID.
- Eliminar.
- Buscar.
- etc.
No hay conexión a base de datos aquí.
Solo definición de métodos.
from abc import ABC, abstractmethod
from typing import List, Optional
from .models import Task
class TaskRepository(ABC):
@abstractmethod
def get_all(self) -> List[Task]:
pass
@abstractmethod
def get_by_id(self, id: int) -> Optional[Task]:
pass2. La implementación (adaptador)
Luego tenemos la clase concreta que implementa esa interfaz.
Aquí es donde conectamos con la realidad. Podemos tener un SQLAlchemyRepository o un FirebaseRepository. Ambos deben cumplir con la firma de la interfaz. Es como un pendrive: no importa qué archivos tenga dentro, el conector USB (la interfaz) siempre es el mismo.
Por ejemplo:
- SQLAlchemyRepository
- FirebaseRepository
- MongoRepository
Esta clase sí contiene la lógica específica para acceder a los datos.
Es como un adaptador en el mundo real: el USB es la interfaz; el cable específico es la implementación.
from sqlalchemy.orm import Session
from .domain import TaskRepository
class SQLAlchemyTaskRepository(TaskRepository):
def __init__(self, db: Session):
self.db = db # Inyectamos la sesión de la DB aquí
def get_all(self) -> List[Task]:
return self.db.query(Task).all()
def get_by_id(self, id: int) -> Optional[Task]:
return self.db.query(Task).filter(Task.id == id).first()3. La capa de acceso mediante dependencias
Aquí es donde entra FastAPI y sus dependencias.
Creamos una función que devuelve una instancia del repositorio. Esa función es nuestra “puerta” de acceso.
Por ejemplo:
from typing import Annotated
from fastapi import Depends
from sqlalchemy.orm import Session
from .database import get_database_session # Tu función con yield
from .infrastructure import SQLAlchemyTaskRepository
from .domain import TaskRepository
# Función que construye el repositorio inyectando la sesión
def get_task_repository(db: Session = Depends(get_database_session)) -> TaskRepository:
return SQLAlchemyTaskRepository(db)
# Creamos un tipo Annotated para que el endpoint sea legible
TaskRepo = Annotated[TaskRepository, Depends(get_task_repository)]Luego usamos Depends() para inyectarlo.
¿Por qué usar anotaciones?
Si vamos a usar esa dependencia muchas veces:
- Obtener tarea por ID.
- Obtener todas.
- Eliminar.
- Filtrar por usuario.
No queremos repetir la misma dependencia todo el tiempo.
Entonces usamos una anotación para simplificar el acceso. Así, si mañana cambiamos la fuente de datos, solo modificamos esa anotación.
4. Consumo desde el endpoint
Finalmente llegamos al endpoint.
Aquí ocurre algo importante:
El endpoint no sabe si los datos vienen de:
- SQLite
- PostgreSQL
- Firebase
- Un archivo JSON
Solo sabe que llama a un método del repositorio.
Eso es desacoplamiento real.
@router.get("/tasks", response_model=List[TaskSchema])
def list_tasks(repo: TaskRepo):
# Aquí 'repo' es una instancia de SQLAlchemyTaskRepository,
# pero el endpoint solo sabe que es un 'TaskRepository'
return repo.get_all()Ejemplo práctico de cambio de base de datos
Supongamos que tu jefe dice:
“No quiero usar SQLAlchemy, eso es viejo. Ahora usamos MongoDB.”
Si tienes el patrón Repository implementado correctamente, solo cambias la implementación concreta.
No tocas:
- Lógica de negocio.
- Endpoints.
- Casos de uso.
Eso es lo bonito de este patrón.
Usamos el sistema de Inyección de Dependencias para decidir qué repositorio usar.
- Anotaciones: Creamos una anotación para no repetir la conexión en cada endpoint.
- Depends: Usamos Depends para inyectar la base de datos o el servicio en el repositorio.
Caso real: mi propia aplicación
En mi plataforma de academia me ha pasado algo similar.
Inicialmente tenía una estructura para cursos. Luego agregué libros. Después agregué pagos genéricos (payment).
Más adelante me di cuenta de que la estructura no era ideal y quería reorganizarla. Si hubiera implementado desde el inicio un patrón más desacoplado, esos cambios serían más sencillos.
También quiero dividir la base de datos porque está creciendo bastante. Con una estructura basada en repositorios, esos cambios serían mucho más manejables.
Relación con arquitectura hexagonal que implementamos antes
En el ejemplo anterior que creamos con la arquitectura hexagonal, tenemos:
- Tenemos una interfaz.
- Tenemos una implementación.
- Tenemos dependencias.
- Tenemos casos de uso.
- Tenemos endpoints.
Sin embargo, la implementación no quedó perfecta. En algunos puntos, la IA rompió el desacoplamiento porque hizo conexiones directas a la base de datos en los controladores:
@router.get("/rooms", response_model=List[Room])
def get_rooms(
room_repo=Depends(get_room_repository),
db: Session = Depends(get_db)
):
"""Get all rooms endpoint."""
# Use ORM directly for this endpoint to maintain relationship loading
# This is a pragmatic choice to avoid complex entity->schema mapping
return db.query(RoomORM).all()Y fíjate que en otro endpoint si lo uso correctamente:
@router.get("/alerts", response_model=List[Alert])
def get_alerts(
room_id: Optional[int] = None,
user: User = Depends(get_current_user),
alert_repo=Depends(get_alert_repository)
):
"""Get alerts endpoint with optional room filtering."""
use_case = GetAlertsUseCase(alert_repo)
alerts = use_case.execute(room_id=room_id)
# Convert entities to ORM-compatible format for Pydantic
return [
{
"id": alert.id,
"content": alert.content,
"created_at": alert.created_at,
"user_id": alert.user_id
}
for alert in alerts
]Usó el repositorio y no empleó la Base de Datos que a diferencia del ejemplo anterior si la incluyó:
room_repo=Depends(get_room_repository),
db: Session = Depends(get_db)Lo cual es un error ya que, el patrón repositorio tienes que desacoplar el como accedes a los datos de la lógica de negocios, ademas de que, NO empleó las anotaciones para definir el acceso al repositorio.
Eso demuestra algo importante:
- Los patrones no se siguen al pie de la letra.
- Se adaptan.
- Se mejoran.
Ventajas Reales (Caso de Uso)
Este enfoque no es solo teoría; tiene aplicaciones prácticas inmediatas:
- Escalabilidad: Puedes tener un repositorio "Gratis" (más lento, en SQL local) y uno "Pro" (más rápido, usando Redis) y alternarlos según el usuario.
- Migraciones sin dolor: Si decides cambiar a MongoDB porque está de moda o por necesidad, solo creas un nuevo repositorio MongoRepository, cambias la inyección de la dependencia y la lógica de tu aplicación permanece intacta.
- Mantenimiento: Como me pasó en mi propia plataforma de cursos, a veces necesitas cambiar cómo se gestionan los pagos o las notas de las clases. Si tienes repositorios separados, puedes evolucionar una parte del sistema sin romper el resto.
Beneficios reales de aplicar Clean Code en FastAPI
Código más fácil de mantener y testear
Ahora puedes testear así:
Sin FastAPI. Sin base de datos.
Escalar sin miedo a romperlo todo
Cuando el proyecto crece:
agregas features sin tocar rutas existentes
cambias infraestructura sin tocar negocio
el código sigue siendo legible
Y ahí entiendes que Clean Code no es un lujo, es una inversión.
Errores comunes al aplicar Clean Architecture en FastAPI
Copiar arquitecturas sin entenderlas
El mayor error es copiar estructuras enormes sin necesidad.
Clean Code no es “copiar carpetas”, es entender responsabilidades.
Convertir Clean Code en burocracia
Si cada cambio requiere 5 archivos nuevos, algo está mal.
La arquitectura debe ayudarte, no frenarte.
cada archivo tiene una responsabilidad
el negocio es independiente
FastAPI no controla tu arquitectura
puedes cambiar DB, framework o estructura sin reescribir todo
Conclusión: Clean Code para no volver a empezar de cero
Clean Code apareció cuando el proyecto empezó a crecer y la estructura inicial ya no alcanzaba. No fue una decisión teórica, fue práctica.
Ahí entendí que no tenía sentido reinventar la rueda cuando ya existían principios pensados exactamente para este problema.
FastAPI te deja avanzar rápido.
Clean Code te permite seguir avanzando sin romperlo todo.
La combinación de ambos es lo que hace que una API pase de “funciona” a “es sostenible”.
FastAPI es grande porque te obliga (o te invita) a pensar en firmas y dependencias. Esta estructura puede parecer compleja al principio ("traída de los pelos"), pero es lo que permite que el código sea testeable, mantenible y extremadamente rápido. Al final del día, a tu endpoint no le interesa cómo obtienes los datos, solo le interesa devolverlos.
Preguntas frecuentes sobre Clean Code en FastAPI
¿Clean Architecture es demasiado para FastAPI?
No, si se aplica con criterio y de forma progresiva.
¿Cuándo debería empezar a aplicarla?
Cuando el proyecto empieza a crecer o sabes que va a hacerlo.
¿Es obligatoria esta estructura?
No. Lo importante es el concepto, no la forma exacta.
¿Vale la pena en proyectos pequeños?
Tal vez no completa, pero sí los principios básicos.
Siguiente paso, FastAPI WebSockets: Guía Completa con Autenticación, REST API y Vue.js
Código fuente:
https://github.com/libredesarrollo/curso-libro-django-vue-channels