
Content Index
- Why a Poor Structure Can Take It Toll
- What Clean Code Means in FastAPI
- Principles That Really Matter in an API
- Clean Architecture as a Natural Consequence
- Separation of Responsibilities in FastAPI
- Layers and dependencies: where the code should point
- Tools: Gemini Antigravity
- Preparation and Architecture Concepts
- What are Clean Architectures and Clean Code?
- Clean Code vs Clean Architecture
- The Prompt and Refactoring
- Execution of the Plan
- The WebSocket Problem
- Result
- Interface Adapters
- Use Cases
- Entities
- Dependencies and the Repository Pattern in FastAPI
- What is the Repository Pattern?
- Why is it useful?
- Beyond changing the database
- Basic structure of the Repository pattern
- 2. The implementation (adapter)
- 3. The access layer through dependencies
- 4. Consumption from the endpoint
- Practical example of changing the database
- Real case: my own application
- Relationship with the hexagonal architecture we implemented before
- Real Advantages (Use Case)
- Real Benefits of Applying Clean Code in FastAPI
- Easier to Maintain and Test Code
- Scale without fear of breaking everything
- Common Mistakes When Applying Clean Architecture in FastAPI
- Copying architectures without understanding them
- Turning Clean Code into Bureaucracy
- Conclusion: Clean Code to Avoid Starting from Scratch
- Frequently Asked Questions about Clean Code in FastAPI
- Frameworks & Drivers
- In this folder, you can see the strongest implementation of technologies that are NOT ours and that we can change at any time, such as FastAPI and the database with SQLAlchemy.
We are going to perform a small experiment. We will take our current project, which doesn't exactly follow the best organizational practices -since it was born as a quick test to implement WebSockets- and we are going to improve its structure. We will do this following the best practices presented earlier in The lifecycle of a FastAPI app with Lifespan events
To do this, we will use established software architectures. I don't intend for this to be a deep course on Go or advanced architectures, but rather a presentation to pique your curiosity. Later, we can dedicate a full section or a specific course to it, or if you prefer, you can investigate on your own. This is the ideal time for this experiment, as the application is small and manageable.
Projects start small, like almost all of them. A couple of endpoints, some routing logic, a database connection… it all seemed reasonable. But as the code grew, maintaining a good structure became essential. That's when I discovered Clean Code applied to FastAPI and understood something key: why reinvent the wheel if the problem is already solved?
In this article, I'll explain how to apply Clean Code to FastAPI in a practical way, without dogma or over-engineering, so your API can grow without becoming a mess.
Why a Poor Structure Can Take It Toll
FastAPI doesn't force you to structure anything. And that's an advantage… until it isn't.
- The typical symptoms:
- Giant routers
- Duplicated logic
- Impossible-to-write tests
- Fear of touching code "because it's bound to break something"
In my case, the project's growth was the trigger. I wasn't writing bad code, but I was writing code that wasn't ready to scale.
What Clean Code Means in FastAPI
Clean Code Isn't About Writing More Layers
A common mistake is thinking that Clean Code means:
“More folders, more classes, and more abstractions.”
No.
Clean Code in FastAPI means:
- clear responsibilities
- well-managed dependencies
- code that is easy to read, test, and modify
It's not about following a trendy architecture, but about solving real maintenance problems.
Principles That Really Matter in an API
When applying Clean Code in FastAPI, these principles make all the difference:
Separation of Responsibilities
HTTP is not business logic.
- Inward Dependencies
Logic doesn't depend on frameworks. - Explicit Code
Understand what it does without reading five files. - Easy Testing
Without launching FastAPI or a real database.
When I understood this, Clean Architecture stopped seeming "academic" and became a natural consequence.
Clean Architecture as a Natural Consequence
Separation of Responsibilities in FastAPI
A well-structured API is typically divided into conceptual layers:
- API / Presentation → FastAPI, routes, request/response
- Application → use cases
- Domain → business rules
- Infrastructure → database, external services
The key: FastAPI resides in the outermost layer.
Layers and dependencies: where the code should point
The golden rule:
Internal layers are unaware that FastAPI exists.
This allows you to:
- replace FastAPI with another framework,
- change the database,
- test logic without HTTP.
And this is where many projects fail if there isn't a clear structure from the outset.
Tools: Gemini Antigravity
For this work, I will use Gemini Anti-Gravity, the editor you see on screen. If you're not familiar with it, it's similar to tools like Windsurf or many others emerging today. It is a fork of VS Code that allows for more effective interaction with AI through agents integrated into the workspace.
One of its most interesting options is Planning. Unlike other extensions for VS Code, this tool generates a "roadmap" before applying any changes. This is extremely useful because it allows you to review and adjust the plan before the AI modifies your code.
Preparation and Architecture Concepts
Before asking the AI for global changes, it is essential to sync your project with GitHub. Things can go wrong, and having a backup will save you a lot of time if you need to revert changes.
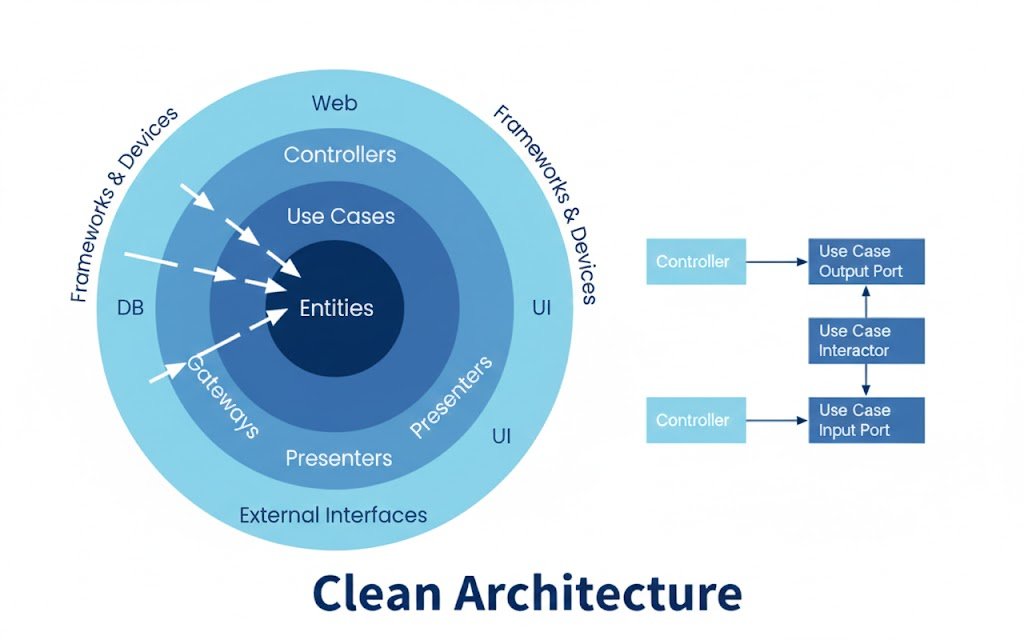
What are Clean Architectures and Clean Code?
You have surely heard about Clean Architecture and Clean Code; let's see what each of them is.
Clean Code vs Clean Architecture
It is important to clarify something:
- Clean Code is not an architecture; it is a philosophy.
- It focuses on writing simple, modular, readable, and maintainable code.
- Clean Architecture is the practical application of those principles.
It's like the difference between API and REST API: one is the general concept and the other is its concrete application.
In essence, Clean Code involves ways of organizing code based on good principles. We have already applied some of this by separating schemas and models, but in an incomplete way. The idea of using an existing architecture is not to reinvent the wheel. Instead of inventing names for our folders, we use proven structures that make the code readable, maintainable, and scalable.
The structure we aim to generate is generally divided into:
- Entities: The purest business logic.
- Use Cases: Specific actions (e.g., creating a user, login). It is the heart of the business logic. Here, it is defined what happens when a user logs in, regardless of whether the request comes from a REST API or a WebSocket.
- This is where the actual system logic resides.
- For example, in login:
- We verify the user.
- We validate the password.
- We generate a token.
- Previously, this was inside the endpoint.
- Now it is decoupled.
- This allows it to:
- Not depend on the response type.
- Not depend on FastAPI.
- Be reusable.
- Interface Adapters: Controllers and repositories that translate data. They act as translators. Here are the controllers that receive HTTP requests and the repositories that handle data.
- They are the translators.
- They receive:
- HTTP Requests
- WebSockets
- XML
- JSON
- And they translate those inputs into use cases.
- Frameworks & Drivers: External tools such as the database or the web framework (FastAPI). This is where code that is "not ours" resides, such as FastAPI configuration or the database connection (SQLAlchemy). If tomorrow we want to change FastAPI for Flask, we should only have to touch this layer.
- Code that isn't ours goes here:
- FastAPI
- Database connection
- ORM
- Mongo, SQLite, Firebase, etc.
- If we change FastAPI for Flask tomorrow, the changes would be here.
- Code that isn't ours goes here:
The Prompt and Refactoring
For the AI to be effective, we need a good Prompt. I have used an AI to generate the instruction that we will give to our code agent. The result was the following:
"Act as a software architecture expert. Refactor my FastAPI application following Clean Code principles. Separate the code into Entities, Use Cases, Interfaces, and Adapters layers. Implement the Repository pattern for data access, ensuring that dependencies point inwards. Generate the new folder structure and the corresponding files."
Execution of the Plan
When activating the Planning option, the AI shows us which files it will create and which folders it will move. In this case, it will create a src folder with subfolders for entities, use cases (like login_use_case.py), and repositories.
The WebSocket Problem
During the refactoring, there was a small error with the WebSockets due to confusion between project versions. The AI initially generated a very simple socket that only returned text. I had to ask for a specific correction:
"Adapt the WebSocket endpoint called websocket_endpoint to the clean architecture, integrating the connection manager (ConnectionManager) we had previously."
Result
Let's look at some important code snippets to understand the previous structure:
A file in its simplest form which is the entry point of the application, where we access the controllers:
main.py
"""Application entry point."""
from src.frameworks_drivers.http.app import appsrc/frameworks_drivers/http/app.py
from src.interface_adapters.controllers import (
auth_controller,
alerts_controller,
rooms_controller,
websocket_controller
)
***
# Include routers with /api prefix
app.include_router(auth_controller.router, prefix="/api")
app.include_router(alerts_controller.router, prefix="/api")
app.include_router(rooms_controller.router, prefix="/api")Interface Adapters
Here are the controllers, which are the gateway to our app. Although it is true that it's impossible to comply 100% with Clean Code principles, there SHOULD NOT be any FastAPI code in this layer. Here we have the FastAPI controllers, which in short, following the MVC scheme, represent the intermediate control layer that connects the View with the Models:
src/interface_adapters/controllers/alerts_controller.py
@router.get("/alerts", response_model=List[Alert])
def get_alerts(
room_id: Optional[int] = None,
user: User = Depends(get_current_user),
alert_repo=Depends(get_alert_repository)
):
"""Get alerts endpoint with optional room filtering."""
use_case = GetAlertsUseCase(alert_repo)
alerts = use_case.execute(room_id=room_id)
# Convert entities to ORM-compatible format for Pydantic
return [
{
"id": alert.id,
"content": alert.content,
"created_at": alert.created_at,
"user_id": alert.user_id
}
for alert in alerts
]In the previous controller example, we see that the database is injected as a dependency because it could be anything: a MariaDB database, PSQL, a JSON file, Firebase, etc. By Clean Code principles, it is handled this way so that it is loosely coupled, meaning we can change the data source without breaking the controllers or other layers.
Additionally, we use use cases where the business logic is handled.
Use Cases
src/use_cases/auth/login.py
"""Login Use Case - Handles user authentication."""
from typing import Optional
import bcrypt
from src.entities.user import User
from src.entities.token import Token
from src.interface_adapters.repositories.repository_interfaces import (
UserRepositoryInterface,
TokenRepositoryInterface
)
class LoginUseCase:
"""Use case for user login."""
def __init__(
self,
user_repository: UserRepositoryInterface,
token_repository: TokenRepositoryInterface
):
self.user_repository = user_repository
self.token_repository = token_repository
def execute(self, username: str, password: str) -> Optional[str]:
"""
Execute login use case.
Args:
username: User's username
password: User's plain password
Returns:
Token key if successful, None otherwise
"""
# Get user by username
user = self.user_repository.get_by_username(username)
if not user:
return None
# Verify password
if not self._verify_password(password, user.password):
return None
# Get or create token
token = self.token_repository.get_by_user_id(user.id)
if not token:
import secrets
token = Token(
key=secrets.token_hex(20),
user_id=user.id
)
token = self.token_repository.create(token)
return token.key
@staticmethod
def _verify_password(plain_password: str, hashed_password: str) -> bool:
"""Verify password against hash."""
password_byte_enc = plain_password.encode('utf-8')
hashed_password_enc = hashed_password.encode('utf-8')
return bcrypt.checkpw(password_byte_enc, hashed_password_enc)In this module, we have our company or business logic. It doesn't care where the data comes from or the expected format. This layer uses a generic entity (neither Pydantic models nor the ORM). Since it's the business logic, in our case—an authenticated user—we handle the cases we covered in the REST API:
rest_api.py
@router.post("/login")
def login(request: schemas.LoginRequest, db: Session = Depends(get_db)):
user = db.query(models.User).filter(models.User.username == request.username).first()
if not user:
return JSONResponse("User invalid", status_code=status.HTTP_401_UNAUTHORIZED)
if not verify_password(request.password, user.password):
return JSONResponse("Password invalid", status_code=status.HTTP_401_UNAUTHORIZED)
# Get or Create Token
token = db.query(models.Token).filter(models.Token.user_id == user.id).first()
if not token:
token = models.Token(user_id=user.id)
db.add(token)
db.commit()
db.refresh(token)
return {"token": f"Token_{token.key}"}But with greater abstraction. As mentioned before, Use Cases DON'T care about the data source (Database or otherwise) or the return type (which isn't specific, as we could use this use case for an API response—what we have—or from a Jinja template, etc.) and it uses a generic entity, again NOT coupled to any framework, which is the next layer.
Entities
We have 3 types of entities. The two we had in our FastAPI project that are strongly coupled to the technology, which in this example is FastAPI:
src/frameworks_drivers/db/orm_models.py
src/interface_adapters/presenters/schemas.py
These are defined in the ORM (strongly linked to code that isn't ours, like the database with SQLAlchemy) and the Pydantic schemas (which, although used by FastAPI, are by definition translators for the FastAPI project).
And finally, we have isolated classes, of the data class type, which just like in Kotlin are classes whose purpose is to present data:
src/entities
"""Alert entity - Core business model."""
from dataclasses import dataclass
from datetime import datetime
from typing import Optional
@dataclass
class Alert:
"""Alert entity representing a message in a room."""
id: Optional[int]
content: str
user_id: int
room_id: int
created_at: Optional[datetime] = NoneTherefore, following Clean Code principles, applications should have loose coupling. Thus, we can change the framework or technology (move to Django or Flask which DO NOT use Pydantic models) and the Use Cases will NOT be altered, which WOULD happen if we used a Pydantic class instead of these entities.
Dependencies and the Repository Pattern in FastAPI
Furthermore, all of the above is also related to the efficiency and speed of FastAPI. Compared to other frameworks, it's typically 5, 7, or even 10 times faster, depending on the implementation. You can easily find this comparison online.
The Repository pattern will help us better understand why dependencies are so important at this point.
To summarize the previous example, we initially have:
- An API to consume something called rooms.
- A resource called alerts, which are basically messages.
- Models to store the data.
- Models for the authenticated user.
- The REST API part.
- And the defined WebSocket.
It is a small exercise, but very interesting for then asking the AI to implement the Repository pattern within a hexagonal architecture with the Repository Pattern and separate the modules correctly.
What is the Repository Pattern?
The Repository Pattern is an abstraction mechanism that allows us to become independent of how and where we store data.
In traditional development, we are usually "tied" to a specific database through an ORM (like SQLAlchemy). While modern frameworks like Django or Flask allow changing the engine (from MySQL to PostgreSQL, for example) with relative ease, the Repository Pattern goes one step further: it allows us to change the entire data source without touching the business logic.
Why is it useful?
Imagine your project grows and, due to client or boss requirements, you can no longer use a relational database. Now you need to consume an external API (like Firebase or Supabase), a JSON file, or even an Excel sheet. Without this pattern, you would have to rewrite almost the entire application. With it, you only change one layer.
Beyond changing the database
With Repository, you can not only change the database engine. You can also completely change the data source:
- An external API.
- Firebase.
- Supabase.
- A JSON file.
- An Excel sheet.
- Any other source.
And you can do it without breaking your application.
If you do it the traditional way, directly referencing models everywhere (following something like a classic MVC), when you change the data source, everything explodes.
With Repository, it doesn't.
Basic structure of the Repository pattern
1. The interface (contract)
In Python, we define an interface using abstract base classes (ABC). Its purpose is to define a "signature": what methods must exist (get, create, delete), but not how they work.
This interface defines the signatures that must be implemented:
- Get all.
- Get by ID.
- Delete.
- Search.
- etc.
There is no database connection here.
Only method definitions.
from abc import ABC, abstractmethod
from typing import List, Optional
from .models import Task
class TaskRepository(ABC):
@abstractmethod
def get_all(self) -> List[Task]:
pass
@abstractmethod
def get_by_id(self, id: int) -> Optional[Task]:
pass2. The implementation (adapter)
Then we have the concrete class that implements that interface.
This is where we connect with reality. We can have a SQLAlchemyRepository or a FirebaseRepository. Both must comply with the interface's signature. It's like a flash drive: no matter what files it has inside, the USB connector (the interface) is always the same.
For example:
- SQLAlchemyRepository
- FirebaseRepository
- MongoRepository
This class does contain the specific logic to access the data.
It's like an adapter in the real world: the USB is the interface; the specific cable is the implementation.
from sqlalchemy.orm import Session
from .domain import TaskRepository
class SQLAlchemyTaskRepository(TaskRepository):
def __init__(self, db: Session):
self.db = db # We inject the DB session here
def get_all(self) -> List[Task]:
return self.db.query(Task).all()
def get_by_id(self, id: int) -> Optional[Task]:
return self.db.query(Task).filter(Task.id == id).first()3. The access layer through dependencies
This is where FastAPI and its dependencies come in.
We create a function that returns an instance of the repository. That function is our "gate" for access.
For example:
from typing import Annotated
from fastapi import Depends
from sqlalchemy.orm import Session
from .database import get_database_session # Your function with yield
from .infrastructure import SQLAlchemyTaskRepository
from .domain import TaskRepository
# Function that builds the repository by injecting the session
def get_task_repository(db: Session = Depends(get_database_session)) -> TaskRepository:
return SQLAlchemyTaskRepository(db)
# We create an Annotated type so that the endpoint is readable
TaskRepo = Annotated[TaskRepository, Depends(get_task_repository)]Then we use Depends() to inject it.
Why use annotations?
If we are going to use that dependency many times:
- Get task by ID.
- Get all.
- Delete.
- Filter by user.
We don't want to repeat the same dependency all the time.
So we use an annotation to simplify access. That way, if tomorrow we change the data source, we only modify that annotation.
4. Consumption from the endpoint
Finally, we reach the endpoint.
Something important happens here:
The endpoint does not know if the data comes from:
- SQLite
- PostgreSQL
- Firebase
- A JSON file
It only knows that it calls a repository method.
That is real decoupling.
@router.get("/tasks", response_model=List[TaskSchema])
def list_tasks(repo: TaskRepo):
# Here 'repo' is an instance of SQLAlchemyTaskRepository,
# but the endpoint only knows it is a 'TaskRepository'
return repo.get_all()Practical example of changing the database
Suppose your boss says:
“I don't want to use SQLAlchemy; that's old. Now we use MongoDB.”
If you have the Repository pattern implemented correctly, you only change the concrete implementation.
You don't touch:
- Business logic.
- Endpoints.
- Use cases.
That is the beauty of this pattern.
We use the Dependency Injection system to decide which repository to use.
- Annotations: We create an annotation so as not to repeat the connection in every endpoint.
- Depends: We use Depends to inject the database or the service into the repository.
Real case: my own application
In my academy platform, something similar happened to me.
Initially, I had a structure for courses. Then I added books. Then I added generic payments.
Later on, I realized that the structure was not ideal and I wanted to reorganize it. If I had implemented a more decoupled pattern from the start, those changes would have been simpler.
I also want to split the database because it is growing quite a bit. With a structure based on repositories, those changes would be much more manageable.
Relationship with the hexagonal architecture we implemented before
In the previous example we created with the hexagonal architecture, we have:
- We have an interface.
- We have an implementation.
- We have dependencies.
- We have use cases.
- We have endpoints.
However, the implementation was not perfect. In some points, the AI broke the decoupling because it made direct connections to the database in the controllers:
@router.get("/rooms", response_model=List[Room])
def get_rooms(
room_repo=Depends(get_room_repository),
db: Session = Depends(get_db)
):
"""Get all rooms endpoint."""
# Use ORM directly for this endpoint to maintain relationship loading
# This is a pragmatic choice to avoid complex entity->schema mapping
return db.query(RoomORM).all()And notice that in another endpoint I do use it correctly:
@router.get("/alerts", response_model=List[Alert])
def get_alerts(
room_id: Optional[int] = None,
user: User = Depends(get_current_user),
alert_repo=Depends(get_alert_repository)
):
"""Get alerts endpoint with optional room filtering."""
use_case = GetAlertsUseCase(alert_repo)
alerts = use_case.execute(room_id=room_id)
# Convert entities to ORM-compatible format for Pydantic
return [
{
"id": alert.id,
"content": alert.content,
"created_at": alert.created_at,
"user_id": alert.user_id
}
for alert in alerts
]It used the repository and did not employ the Database which, unlike the previous example, it did include:
room_repo=Depends(get_room_repository),
db: Session = Depends(get_db)Which is an error since, in the repository pattern, you have to decouple how you access the data from the business logic; furthermore, it did NOT employ annotations to define access to the repository.
That demonstrates something important:
- Patterns are not followed to the letter.
- They are adapted.
- They are improved.
Real Advantages (Use Case)
This approach is not just theory; it has immediate practical applications:
- Scalability: You can have a "Free" repository (slower, on local SQL) and a "Pro" one (faster, using Redis) and switch them according to the user.
- Painless migrations: If you decide to change to MongoDB because it's trendy or necessary, you just create a new MongoRepository implementation, change the dependency injection, and your application logic remains intact.
- Maintenance: As happened to me on my own course platform, sometimes you need to change how payments or class notes are managed. If you have separate repositories, you can evolve one part of the system without breaking the rest.
Real Benefits of Applying Clean Code in FastAPI
Easier to Maintain and Test Code
Now you can test like this:
async def test_create_user():
repo = InMemoryUserRepository()
use_case = CreateUser(repo)
user = await use_case.execute(data)
assert user.email == "test@test.com"Without FastAPI. Without a database.
Scale without fear of breaking everything
When the project grows:
- add features without touching existing routes
- change infrastructure without affecting the business
- the code remains readable
And that's when you understand that Clean Code isn't a luxury, it's an investment.
Common Mistakes When Applying Clean Architecture in FastAPI
Copying architectures without understanding them
The biggest mistake is copying huge structures unnecessarily. Clean Code isn't about "copying folders," it's about understanding responsibilities.
Turning Clean Code into Bureaucracy
If every change requires 5 new files, something is wrong. Architecture should help you, not hold you back.
Conclusion: Clean Code to Avoid Starting from Scratch
Clean Code emerged when the project began to grow and the initial structure was no longer sufficient. It wasn't a theoretical decision; it was practical.
That's when I understood that it didn't make sense to reinvent the wheel when principles already existed that were designed precisely for this problem.
FastAPI lets you move forward quickly. Clean Code allows you to keep moving forward without breaking everything.
The combination of both is what makes an API go from "working" to "sustainable."
FastAPI is great because it forces (or encourages) you to think about signatures and dependencies. This structure may seem complex at first ("far-fetched"), but it's what allows the code to be testable, maintainable, and extremely fast. At the end of the day, your endpoint isn't interested in how you get the data; it's only interested in returning it.
Frequently Asked Questions about Clean Code in FastAPI
- Is Clean Architecture too much for FastAPI?
- No, if it's applied judiciously and progressively.
- When should I start applying it?
- When the project starts to grow, or you know it will.
- Is this structure mandatory?
- No. The important thing is the concept, not the exact form.
- Is it worthwhile for small projects?
- Perhaps not in its entirety, but the basic principles are certainly useful.
Frameworks & Drivers
In this folder, you can see the strongest implementation of technologies that are NOT ours and that we can change at any time, such as FastAPI and the database with SQLAlchemy.
Next step, FastAPI WebSockets: A Complete Guide with Authentication, REST API, and Vue.js
Source code:
https://github.com/libredesarrollo/curso-libro-django-vue-channels